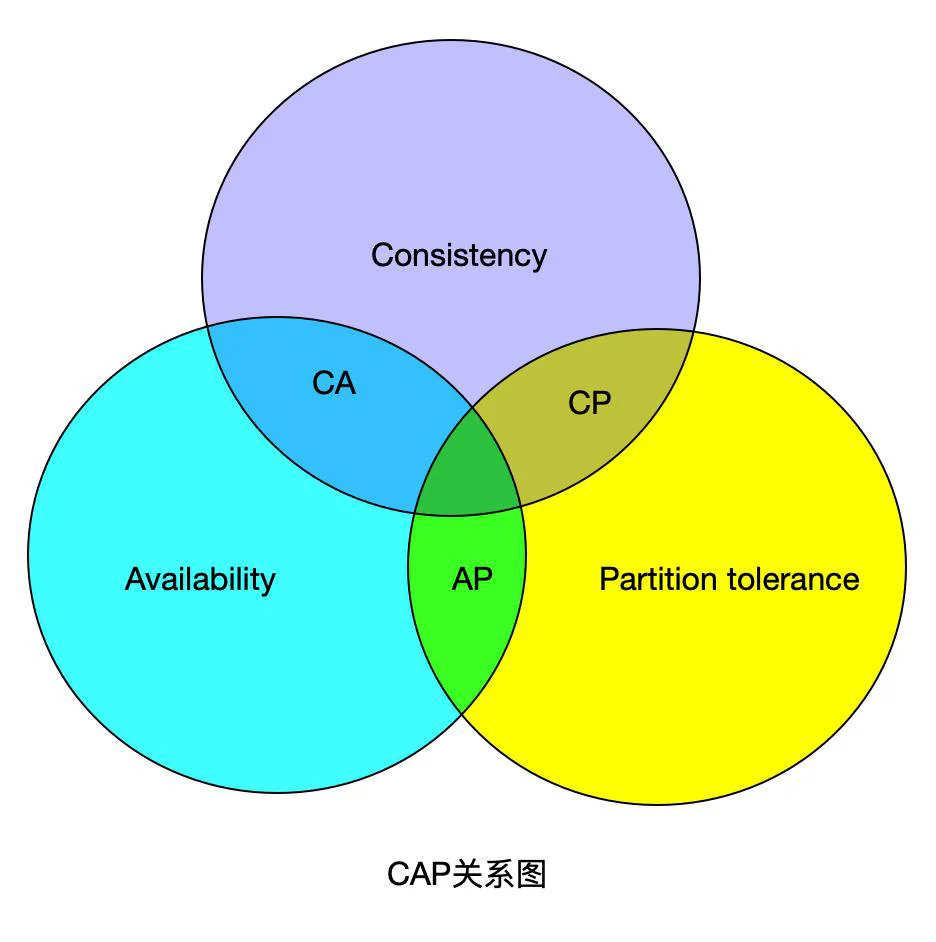
CAP 定理是分布式系统中的基础核心定理,该定理明确表明任何一套分布式系统,最多只能同时满足以下三大核心特性中的两项。
一致性(Consistency)
可用性(Availability)
分区容错性(Partition tolerance)
CAP 定理明确界定分布式系统无法同时兼顾一致性、可用性、分区容错性三大特性。想要理清该结论成立的底层逻辑,首先要弄懂一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance)三者的精准定义,同时明确分布式系统的基础概念。
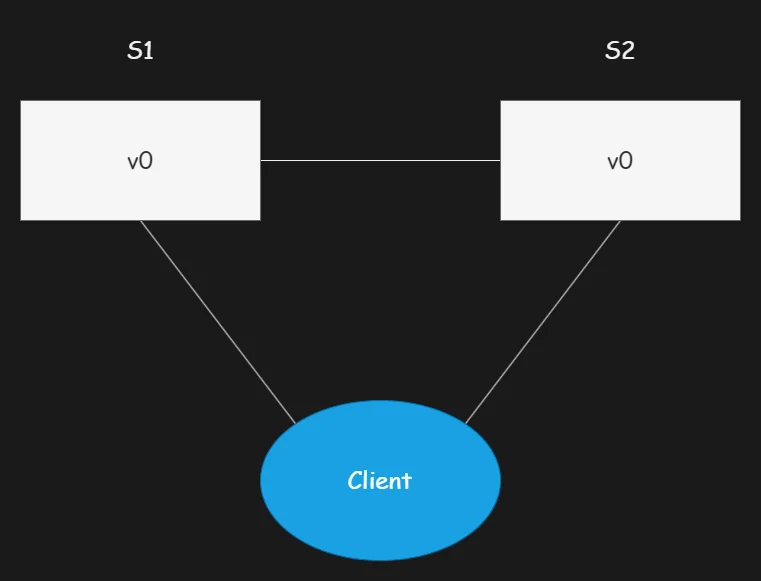
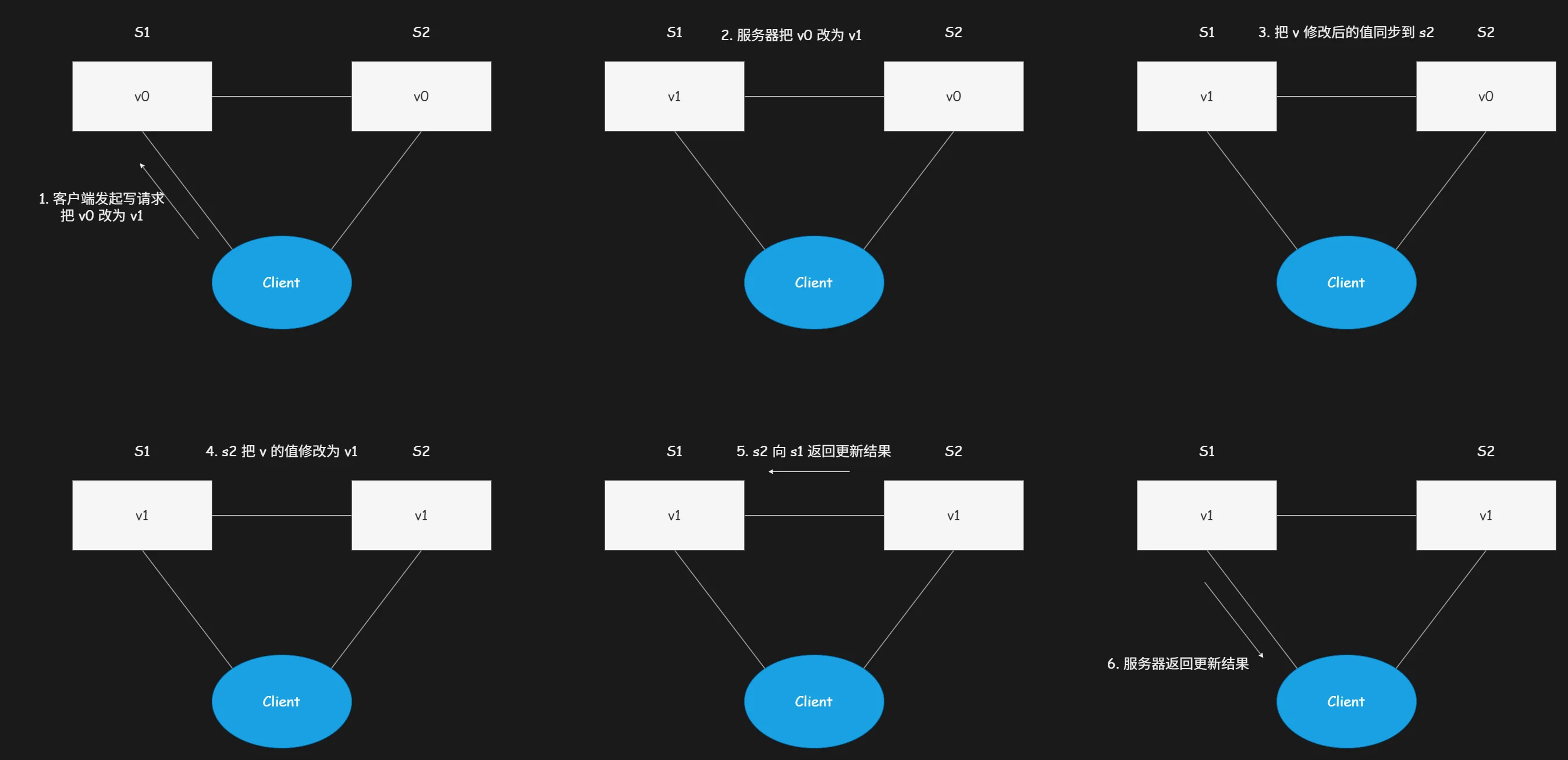
我们搭建一套极简分布式系统模型,由 2 台服务器 S1 和 S2 构成;两台服务器统一存储同一个变量 v,变量初始值为 V0;S1 与 S2 可互相通信,同时也能对接外部客户端完成交互,该分布式系统基础架构示意图如下:
客户端可随意向任意一台服务器发起读写请求,服务器接收请求后完成对应业务逻辑处理,最终将处理结果回传给客户端。
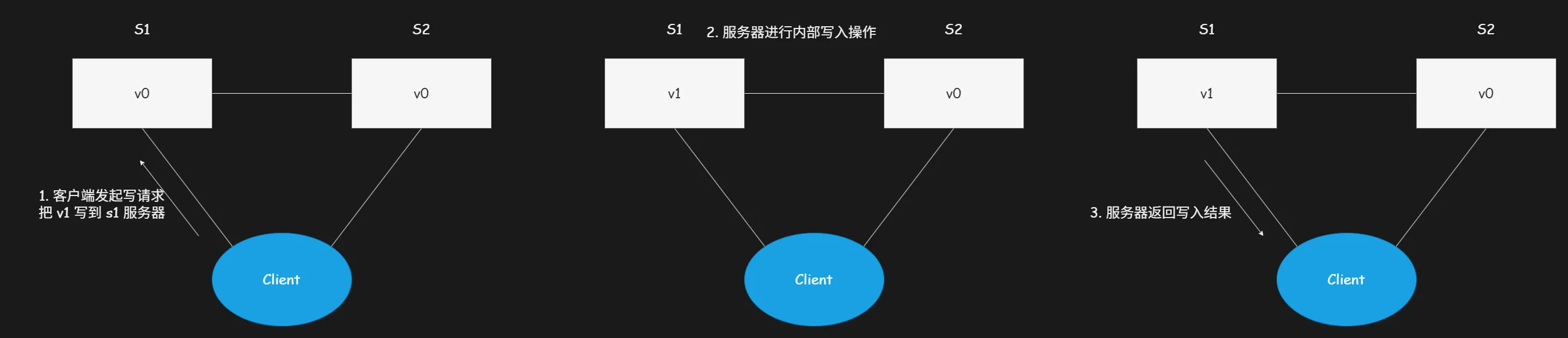
客户端发起写请求流程示意图:
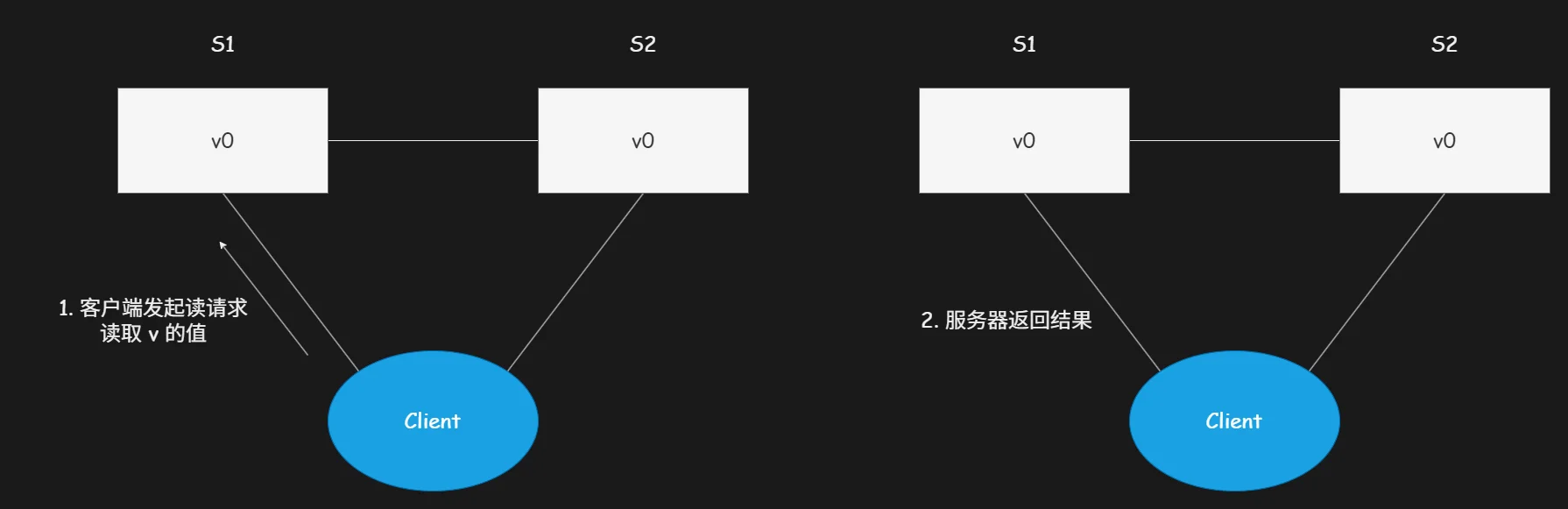
客户端发起读请求流程示意图:
极简分布式系统基础模型搭建完成,下文将依托该模型,详细拆解 CAP 定理中三大核心特性的实际含义与应用逻辑。
一致性标准定义:系统完成一次写操作后,后续所有读操作都必须读取到本次写入值,或是后续最新写入的数值。满足强一致性的分布式系统中,客户端向集群内任意一台服务器提交写请求,之后向集群内其余任意服务器发起读请求查询数据,都能精准获取到最新更新完成的数据结果。
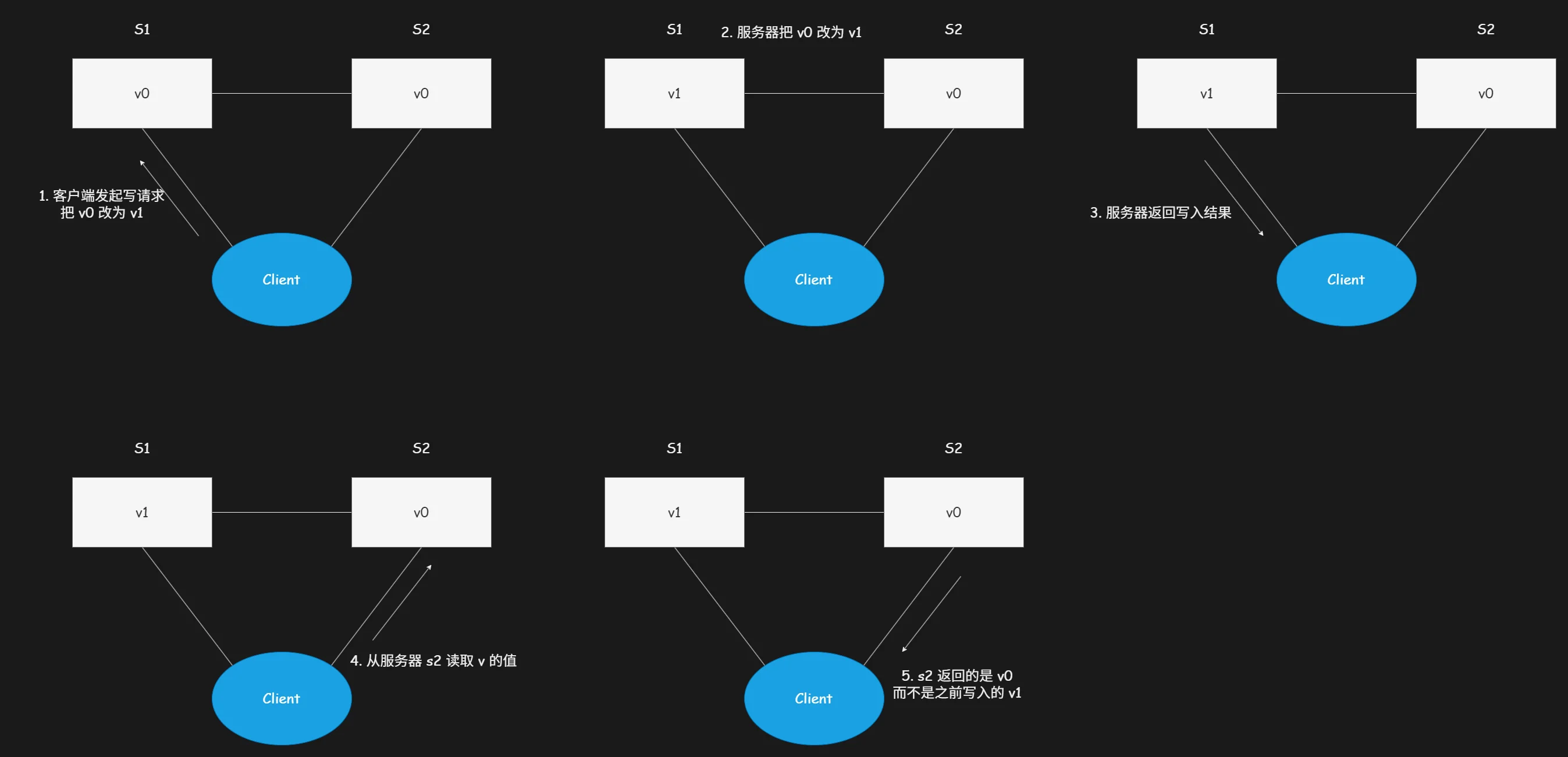
客户端向集群内 S1 服务器发起写请求(write V1),收到成功响应结果后,随即向 S2 服务器发起读请求读取对应变量数值,S2 服务器依旧返回原始旧值 V0。实际返回数据与客户端预期最新数据不符,此时该分布式系统出现明显的数据一致性异常问题。
客户端向 S1 服务器发起写请求(write V1),S1 完成本地数据写入后,主动将最新数值同步推送至 S2 服务器;等待 S2 服务器完成数据落地并返回写入成功回执后,S1 才会向客户端反馈写入成功。此时客户端从 S2 服务器读取变量 v 的数值,可正常获取到最新值 V1,与预期结果完全匹配,该分布式系统成功保障数据强一致性。
补充知识点:CAP 定理中提及的一致性特指强一致性,在实际业务开发中,还包含最终一致性、会话一致性、因果一致性等弱一致性方案,也是当下主流业务常用的数据一致方案。
可用性核心标准:在分布式系统正常运行状态下,客户端向任意一台未出现故障的服务器发起业务请求,该服务器必须在合理时间内完成处理,并最终向客户端返回有效响应结果。评判分布式系统可用性高低,行业内普遍以系统年度停机时长作为核心衡量依据,非故障节点必须对合法请求做出有效应答。
互联网线上业务系统、核心政务系统、金融交易系统等关键业务场景,行业通用标准为达到 5 个 9 可用性(99.999 %),最大限度降低服务中断带来的业务损失。
分区容错性含义:当分布式集群内部出现节点宕机、网络中断等网络分区故障时,整套系统依旧可以对外持续提供基础服务,尽可能保障业务正常运转。
典型场景:S1 服务器与 S2 服务器之间网络链路断开形成网络分区,具备分区容错性的分布式系统,依旧可以正常对接外部客户端,提供读写服务。
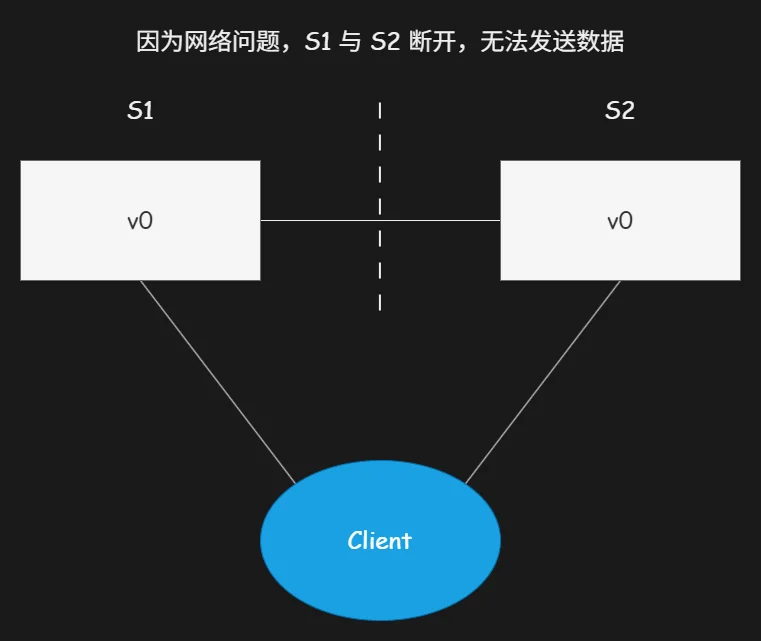
核心行业共识:网络不稳定、链路中断是分布式环境下无法规避的客观问题,所有分布式系统天然必须满足分区容错性 P,不存在舍弃分区容错性的成熟分布式架构。
假设强行让分布式系统同时满足一致性、可用性、分区容错性三大特性,我们人为制造集群网络分区故障进行推演验证。
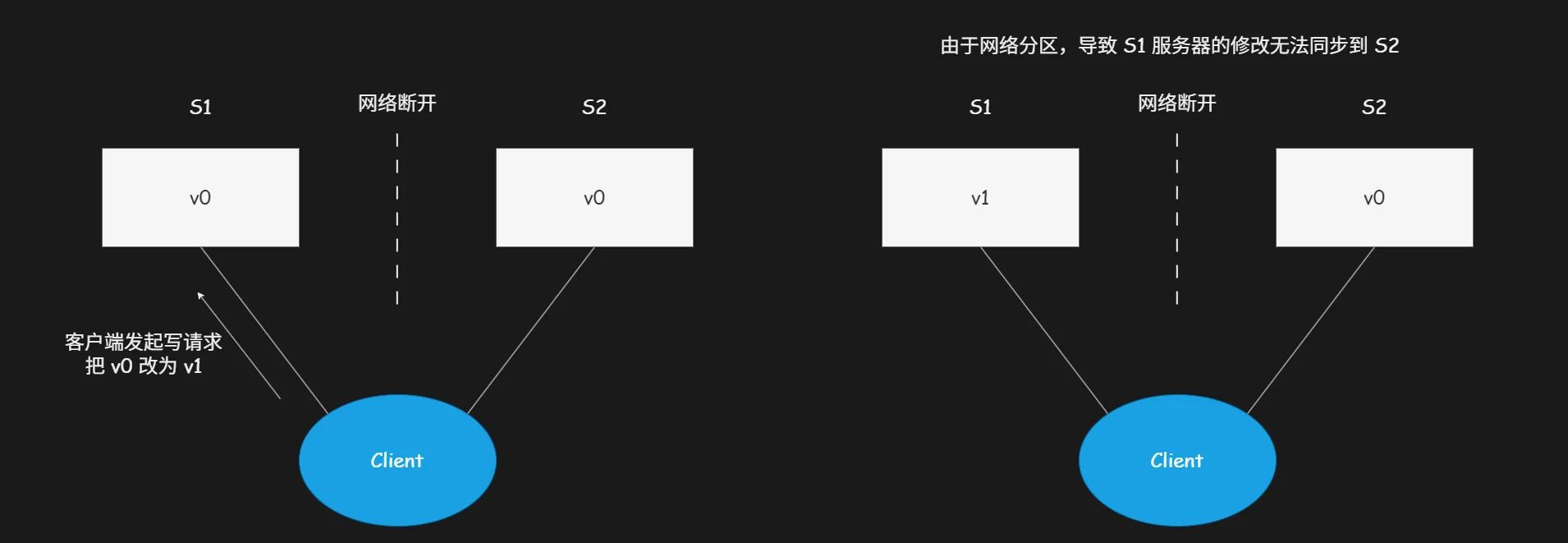
断开 S1 与 S2 服务器之间的通信链路,形成典型网络分区。客户端向 S1 服务器发起数据更新请求,将变量 v 的数值从 V0 修改为 V1,S1 顺利完成本地数据更新。由于两台服务器网络中断,S1 无法将最新数据同步传输至 S2 服务器;而系统需要保障可用性,必须及时向客户端返回请求响应,最终造成 S2 服务器留存旧数据。
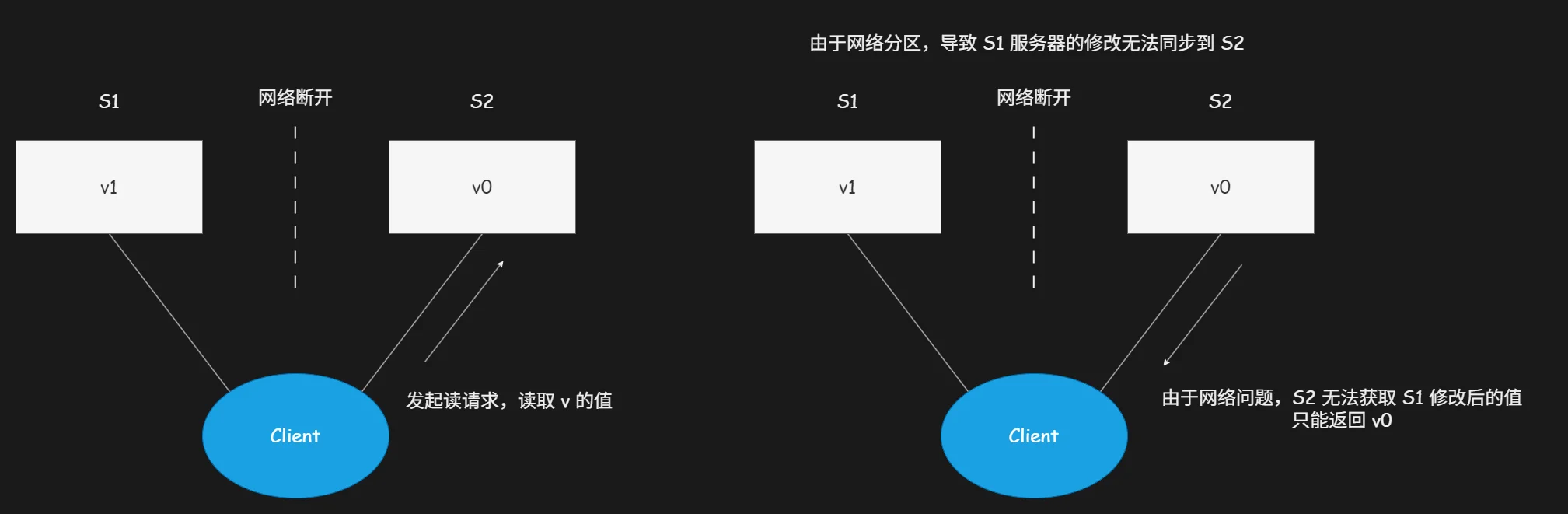
后续客户端向 S2 服务器发起数据读取请求,为坚守可用性原则,S2 只能直接返回本地存储的旧数据,此时集群内节点数据出现偏差,系统彻底丧失数据一致性。通过完整逻辑推演可证实:在存在网络分区的分布式环境中,一致性与可用性无法同时兼顾,三大特性无法同时满足。
结合 CAP 定理核心结论,分布式系统无法同时兼容 C、A、P 三大特性,结合分布式环境网络分区不可避免的特性,实际架构选型仅存在两大主流方向,舍弃方案如下:
CA without P:舍弃分区容错性,保留一致性与可用性
CP without A:舍弃可用性,保留一致性与分区容错性
AP without C:舍弃强一致性,保留可用性与分区容错性
该架构模式在实际分布式项目中几乎不存在。网络分区是分布式集群运行过程中必然会出现的故障场景,主动舍弃分区容错性,等同于放弃分布式架构设计思路,回归单体架构,因此该选型无实际落地价值,这也是 CAP 定理论证以分区容错性为前置条件的核心原因
该选型放弃服务高可用能力,优先保障数据强一致性与分区容错性。当集群出现网络故障、数据同步延迟等问题时,系统会暂停对外服务,等待集群内所有节点数据完成统一同步后,再恢复业务访问。主流应用场景:分布式事务处理系统、ZooKeeper 协调集群、金融核心账务系统等,这类业务对数据精准度要求极高,可容忍短暂服务不可用
该选型优先保障系统高可用与分区容错性,主动舍弃实时强一致性,采用最终一致性方案完成数据同步。一旦集群发生网络分区故障,各个独立节点仅依托本地存量数据对外提供服务,优先保障客户端请求快速响应,后续待网络恢复正常后,再异步完成全集群数据统一同步。该模式是互联网主流业务首选架构,适用场景十分广泛,例如电商平台商品浏览、12306 票务查询、社交平台动态发布、短视频流量分发等,优先保障用户正常访问体验,数据短暂不一致不会造成严重业务风险
在互联网网络通信领域,网络是不可靠的是通用底层设计原则,该原则直接决定分布式系统架构设计思路,同时也影响网络通信协议选型与功能实现逻辑。
物理层问题:通信线路损坏、网络硬件设备故障、机房线路波动等
传输层问题:网络数据包丢失、数据传输延迟、数据包乱序抵达等
网络拥塞:网络访问流量超出链路承载上限,引发数据包主动丢弃
路由问题:路由配置错误、路由节点故障,导致数据包无法正常送达目标节点
安全攻击:网络恶意攻击、流量劫持等行为,造成网络中断或数据篡改
成因:路由器缓存队列溢出、物理通信链路故障、网络限流拦截
优化方案:依托 TCP 协议自动重传机制,搭配业务层重试逻辑弥补数据丢失问题
成因:全网流量拥塞、网络节点数据处理耗时过长、跨地域传输距离较远
优化方案:业务层增设超时判定机制,结合业务场景合理配置超时阈值
成因:数据包选择不同传输路径转发,不同路径传输时延存在差值
优化方案:在数据接收端增设排序逻辑,按照原始发送顺序重组数据
成因:网络重传机制触发,同一业务数据包被多次重复发送
优化方案:为数据包配置唯一序列号,接收端自动识别并剔除重复数据
成因:中间人网络劫持、恶意程序篡改传输数据
优化方案:采用 SSL/TLS 加密传输协议,保障传输数据完整性与安全性
容错设计:提前预判各类网络故障,搭建多线路冗余通信路径,配置集群服务备份节点
优雅降级:网络环境异常时,关闭非核心附加功能,优先保障核心基础业务正常运行
用户反馈:前端搭配清晰的异常提示、加载进度提示,优化网络异常场景下的用户使用体验
测试和监控:定期开展网络压力测试、故障模拟测试,搭建全链路网络监控体系,第一时间排查并修复网络隐患