在现实世界的业务系统中,数据很少只存储在一张表中。
员工信息在 emp 表。
部门名称在 dept 表。
订单详情在 order_item 表,而商品信息在 goods 表。
如果我们需要查询“研发部所有员工的姓名和工资”,就需要将这两张表的数据关联起来。这就是多表联查(Multi-table Join)的核心价值:将分散在不同表中的相关数据,通过逻辑关系整合成一张完整的视图。
为了演示,我们构建一个经典的“员工 - 部门”模型
DROP TABLE IF EXISTS emp;
DROP TABLE IF EXISTS dept;
-- 1. 创建部门表 (父表)
CREATE TABLE dept (
did INT PRIMARY KEY AUTO_INCREMENT COMMENT '部门ID',
dname VARCHAR(20) NOT NULL COMMENT '部门名称'
);
-- 2. 创建员工表 (子表)
CREATE TABLE emp (
id INT PRIMARY KEY AUTO_INCREMENT COMMENT '员工ID',
name VARCHAR(10) NOT NULL COMMENT '姓名',
gender CHAR(1) COMMENT '性别',
salary DOUBLE(7, 2) COMMENT '工资',
join_date DATE COMMENT '入职日期',
dep_id INT COMMENT '所属部门ID',
-- 定义外键约束
CONSTRAINT fk_emp_dept FOREIGN KEY (dep_id) REFERENCES dept(did)
);
-- 3. 插入部门数据
INSERT INTO dept (dname) VALUES ('研发部'), ('市场部'), ('财务部'), ('销售部');
-- 4. 插入员工数据
-- 注意:罗刹的 dep_id 为 NULL,表示他目前没有分配部门
INSERT INTO emp (name, gender, salary, join_date, dep_id) VALUES
('李星云', '男', 7200.00, '2013-02-24', 1),
('刃', '男', 3600.00, '2010-12-02', 2),
('丹恒', '男', 9000.00, '2008-08-08', 2),
('镜流', '女', 5000.00, '2015-10-07', 3),
('藿藿', '女', 4500.00, '2011-03-14', 1),
('罗刹', '男', 2500.00, '2011-02-14', NULL);如果在查询多表时没有指定连接条件,数据库会将表 A 的每一行与表 B 的每一行进行组合。
公式:结果行数 = 表 A 行数 × 表 B 行数。
后果:产生大量无意义的“脏数据”。
错误示范
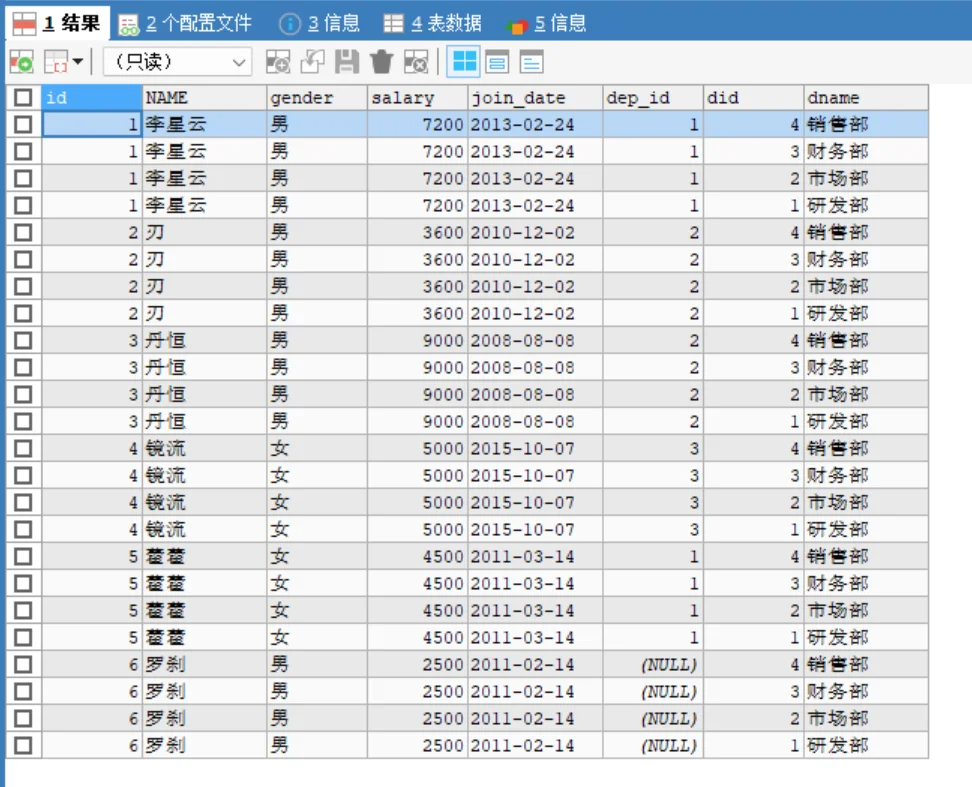
SELECT * FROM emp, dept;
-- 结果:6名员工 × 4个部门 = 24条记录
-- 问题:李星云明明属于研发部(1),结果里却出现了他属于市场部(2)、财务部(3)的错误记录。必须添加连接条件,通常是 子表.外键 = 父表.主键。
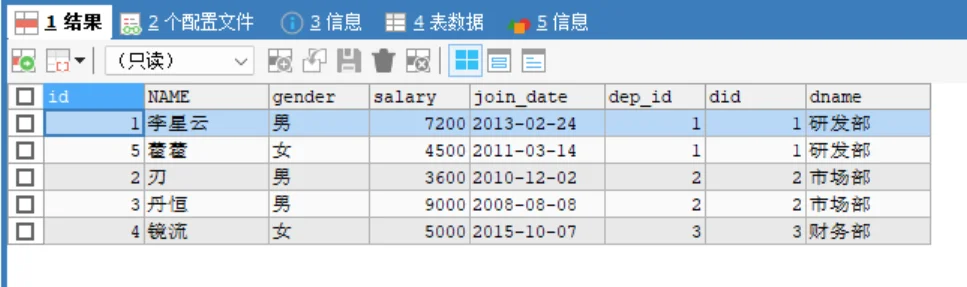
SELECT * FROM emp, dept WHERE emp.dep_id = dept.did;效果:只保留
dep_id和did相等的行,得到正确的 5 条匹配记录(罗刹因 dep_id 为 NULL 被过滤)。
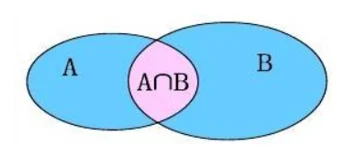
内连接查询只返回两个表中连接字段相匹配的行。
形象理解:取两个集合的交集 (A ∩ B)。
特点:如果某行在另一个表中没有匹配项,则该行不会出现在结果中。
使用 WHERE 子句指定条件(旧式写法,推荐在新项目中避免使用,易混淆)。
SELECT 字段列表 FROM 表1, 表2 WHERE 表1.列 = 表2.列;使用 JOIN ... ON 语法,结构更清晰,将连接条件与过滤条件分离。
SELECT 字段列表 FROM 表1 [INNER] JOIN 表2 ON 表1.列 = 表2.列;注:INNER 关键字可以省略,默认就是内连接。
需求:查询所有有部门的员工及其部门名称。
SELECT
e.name AS 员工姓名,
e.salary AS 工资,
d.dname AS 部门名称
FROM emp e
INNER JOIN dept d ON e.dep_id = d.did;执行结果
李星云、刃、丹恒、镜流、藿藿:都有对应的 dep_id,显示。
罗刹:dep_id 为 NULL,无法匹配任何部门,不显示。
当我们需要保留某张表的所有数据,即使它在另一张表中没有匹配项时,就需要用到外连接。
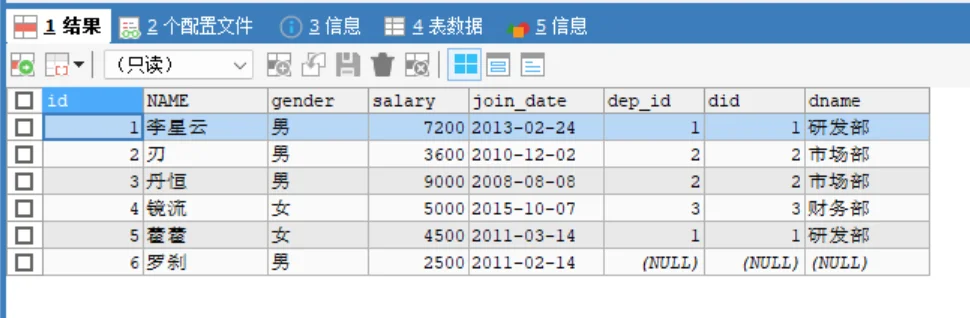
定义:以左表为主表,返回左表的所有行。如果右表中没有匹配,则右表列显示为 NULL。
形象理解:左表全量 + 交集 (A + A∩B)。
语法:
SELECT 字段列表 FROM 左表 LEFT [OUTER] JOIN 右表 ON 连接条件;实战案例:查询所有员工的信息,包括没有部门的员工。
SELECT
e.name AS 员工姓名,
d.dname AS 部门名称
FROM emp e
LEFT JOIN dept d ON e.dep_id = d.did;结果特点
李星云等 5 人:正常显示部门名称。
罗刹:依然显示在结果中,但其“部门名称”列显示为 NULL。
应用场景:统计“所有员工的部门分布情况”,不能漏掉未分配部门的员工。
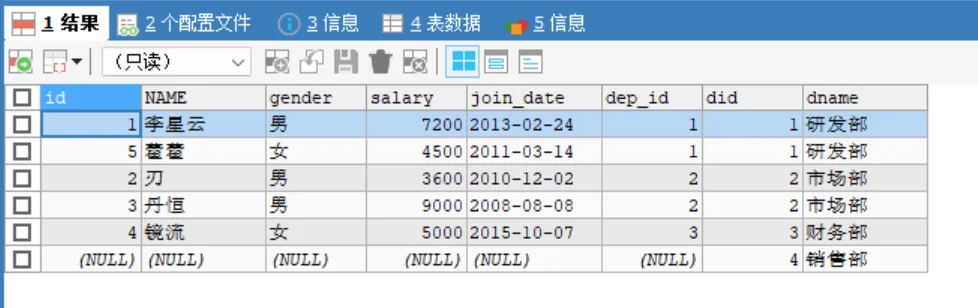
定义:以右表为主表,返回右表的所有行。如果左表中没有匹配,则左表列显示为 NULL。
形象理解:右表全量 + 交集 (B + A∩B)。
语法:
SELECT 字段列表 FROM 左表 RIGHT [OUTER] JOIN 右表 ON 连接条件;实战案例:查询所有部门,即使该部门目前没有员工。
SELECT
d.dname AS 部门名称,
e.name AS 员工姓名
FROM emp e
RIGHT JOIN dept d ON e.dep_id = d.did;结果特点:
研发部、市场部、财务部:显示对应员工。
销售部:因为没有员工指向它(dep_id=4 不存在于 emp 表),该部门依然显示,但“员工姓名”列为 NULL。
最佳实践
在 MySQL 中,LEFT JOIN和RIGHT JOIN逻辑是互通的。通常建议统一使用LEFT JOIN,通过交换表的位置来实现相同逻辑,这样代码阅读顺序更符合“从左到右”的习惯。
例如:A RIGHT JOIN B等价于B LEFT JOIN A。
子查询是指嵌套在另一个 SQL 语句(外部查询)内部的 SELECT 语句。它允许我们将复杂的查询分解为多个步骤。
场景:子查询结果只有一个值,常用于 WHERE 条件中的比较运算 (=, >, <)。
需求:查询工资高于 “刃” 的员工信息。
思路:
先查出“刃”的工资。
再查工资高于该数值的员工。
SELECT * FROM emp
WHERE salary > (
SELECT salary FROM emp WHERE name = '刃'
);执行过程:内部查询返回 3600 -> 外部查询变为 WHERE salary > 3600。
场景:子查询结果是一列数据,常用于 WHERE 条件中的 IN, NOT IN, ANY, ALL。
需求:查询 “财务部” 和 “市场部” 的所有员工信息。
思路:
先查出这两个部门的 ID (did)。
再查 dep_id 在这些 ID 中的员工。
SELECT * FROM emp
WHERE dep_id IN (
SELECT did FROM dept WHERE dname IN ('财务部', '市场部')
);执行过程:内部查询返回 (3, 2) -> 外部查询变为 WHERE dep_id IN (3, 2)。
场景:子查询结果是一张临时表(虚拟表),常用于 FROM 子句之后。必须给子查询结果起别名。
需求:查询 2011-11-11 之后入职的员工及其部门信息。
思路:
先筛选出符合条件的员工,形成一张临时表。
将这张临时表与部门表进行连接。
SELECT t1.name, t1.join_date, t2.dname
FROM (
SELECT * FROM emp WHERE join_date > '2011-11-11'
) AS t1 -- 必须起别名 t1
INNER JOIN dept t2 ON t1.dep_id = t2.did;