数据库是软件系统的“地基”。如果地基不稳(设计不合理),上层建筑(应用程序)无论代码写得多么优美,都会面临数据冗余、查询缓慢、数据不一致甚至系统崩溃的风险。
数据库设计不仅仅是建表,它是一个系统性的工程,旨在:
准确映射业务:将现实世界的业务逻辑转化为数据结构。
保障数据质量:通过规范减少错误和异常。
优化性能:合理的结构能显著提升查询效率,降低存储成本。
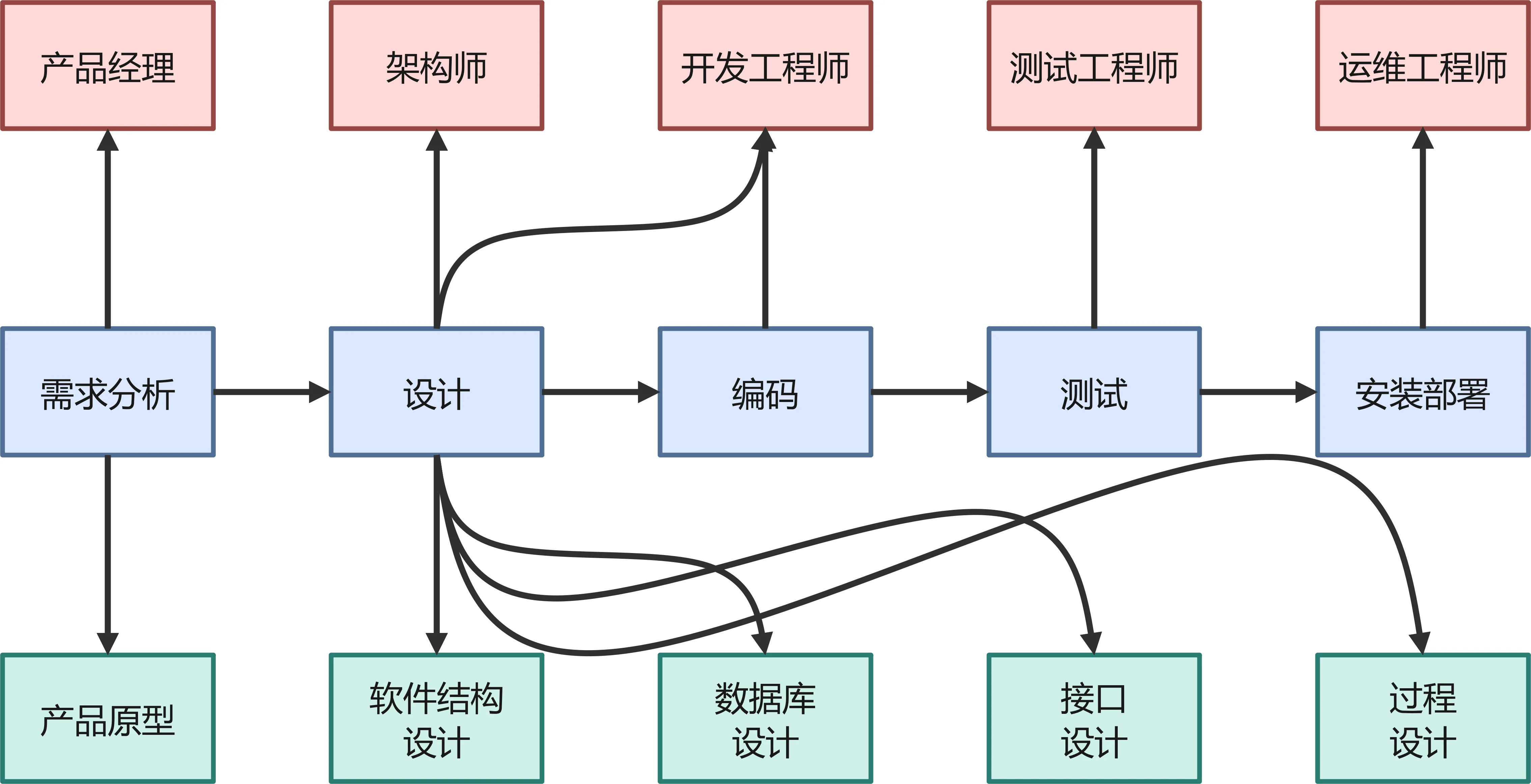
一个标准的数据库设计通常遵循以下七个步骤,贯穿软件开发生命周期:
目标:搞清楚“存什么数据?”、“数据有什么特点?”、“数据之间有什么关系?”。
产出:数据字典、业务流程图。
关键问题:
用户需要记录哪些信息?(如:学生的姓名、成绩)
数据的取值范围是什么?(如:性别只能是男 / 女)
数据的访问频率如何?(高频查询字段需重点优化)
目标:脱离具体的数据库软件(如 MySQL、Oracle),用抽象模型描述数据。
核心工具:E-R 图 (Entity-Relationship Diagram)。
要素:
实体 (Entity):矩形表示(如:学生、课程)。
属性 (Attribute):椭圆表示(如:姓名、学号)。
关系 (Relationship):菱形表示(如:选课、属于)。
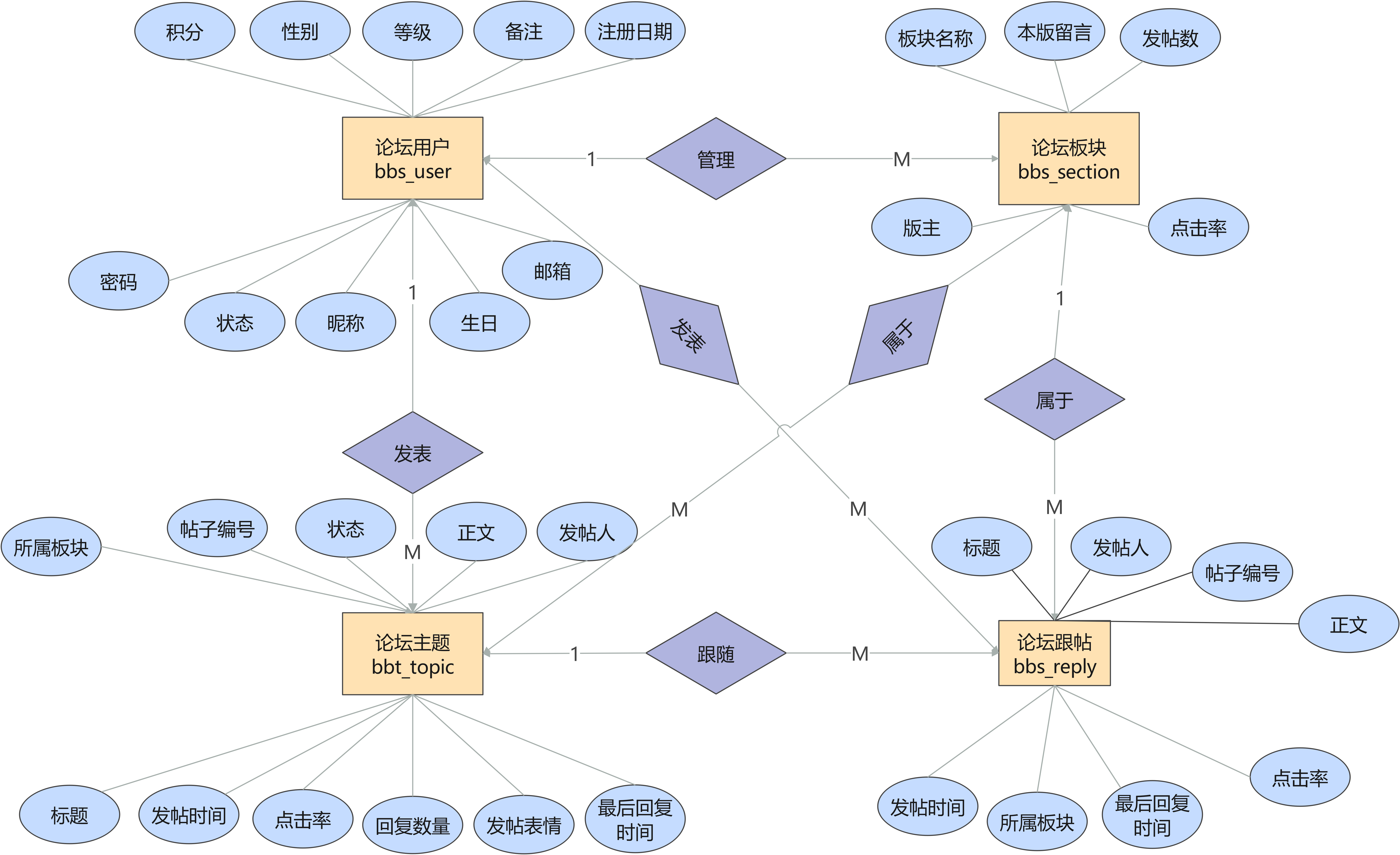
目标:将 E-R 图转化为特定 DBMS 支持的数据模型(通常是关系模型)。
动作:
确定表结构(Table)。
确定字段(Column)及其数据类型。
确定主键(Primary Key)和外键(Foreign Key)。
规范化:应用三大范式消除冗余。
目标:针对具体的 MySQL 引擎进行优化。
动作:
选择存储引擎(如 InnoDB, MyISAM)。
设计索引(Index)以加速查询。
规划分区(Partitioning)处理大数据量。
设定字符集(如 utf8mb4)。
实施:编写 SQL 脚本创建库、表、视图、触发器。
维护:随着业务变化,进行表结构变更(Alter)、数据迁移或性能调优。
在关系型数据库中,表与表之间的关系主要有三种:一对一、一对多、多对多。正确识别并实现这些关系是数据库设计的核心。
One-to-One
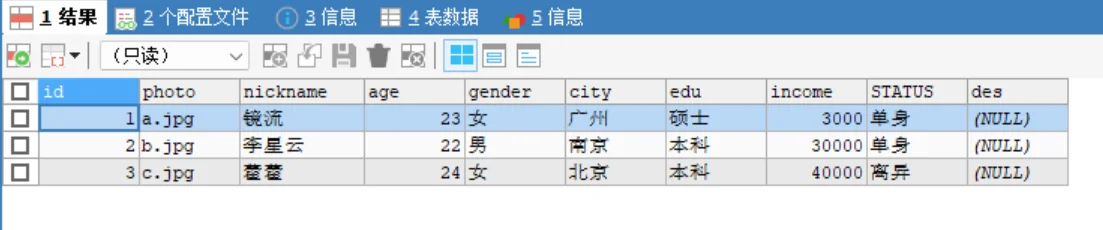
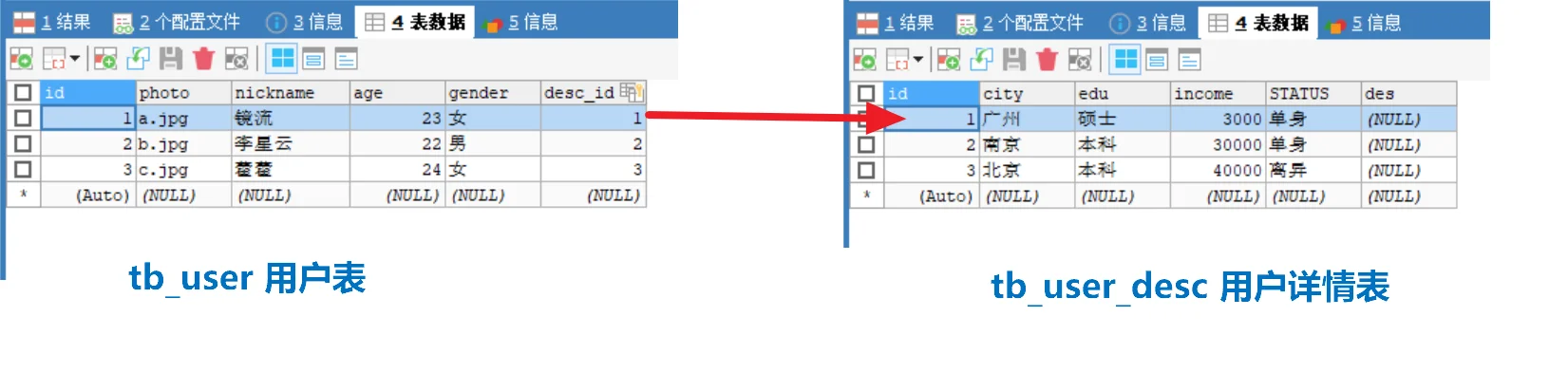
定义:表 A 中的一条记录只能对应表 B 中的一条记录,反之亦然。
典型案例:
用户 与 用户详情(身份证、生物特征等敏感或不常用信息)。
员工 与 工牌。
设计目的:垂直拆分。将常用字段和不常用字段分开,减少单次查询的数据量,提升内存利用率。
在任意一方表中添加外键,关联另一方的主键,并将该外键设置为 UNIQUE (唯一)。
用户与用户详情
我们将用户基本信息(高频访问)与详细信息(低频访问)拆分。
-- 1. 创建用户详情表 (被关联表)
CREATE TABLE tb_user_desc (
id INT PRIMARY KEY AUTO_INCREMENT COMMENT '详情ID',
city VARCHAR(20) COMMENT '城市',
edu VARCHAR(10) COMMENT '学历',
income INT COMMENT '收入',
status CHAR(2) COMMENT '状态',
description TEXT COMMENT '个人简介'
);
-- 2. 创建用户主表 (关联表)
CREATE TABLE tb_user (
id INT PRIMARY KEY AUTO_INCREMENT COMMENT '用户ID',
photo VARCHAR(100) COMMENT '头像',
nickname VARCHAR(50) COMMENT '昵称',
age INT COMMENT '年龄',
gender CHAR(1) COMMENT '性别',
-- 核心:外键 + 唯一约束
desc_id INT UNIQUE,
CONSTRAINT fk_user_desc FOREIGN KEY (desc_id) REFERENCES tb_user_desc(id)
);数据插入示例:
-- 先插详情
INSERT INTO tb_user_desc (id, city, edu, income, status) VALUES
(1, '广州', '硕士', 30000, '单身'),
(2, '南京', '本科', 15000, '已婚');
-- 再插用户 (关联详情ID)
INSERT INTO tb_user (nickname, age, gender, desc_id) VALUES
('镜流', 23, '女', 1),
('李星云', 22, '男', 2);
注意:由于
desc_id有UNIQUE约束,同一个详情 ID 不能被两个用户引用,从而保证了一对一。
One-to-Many
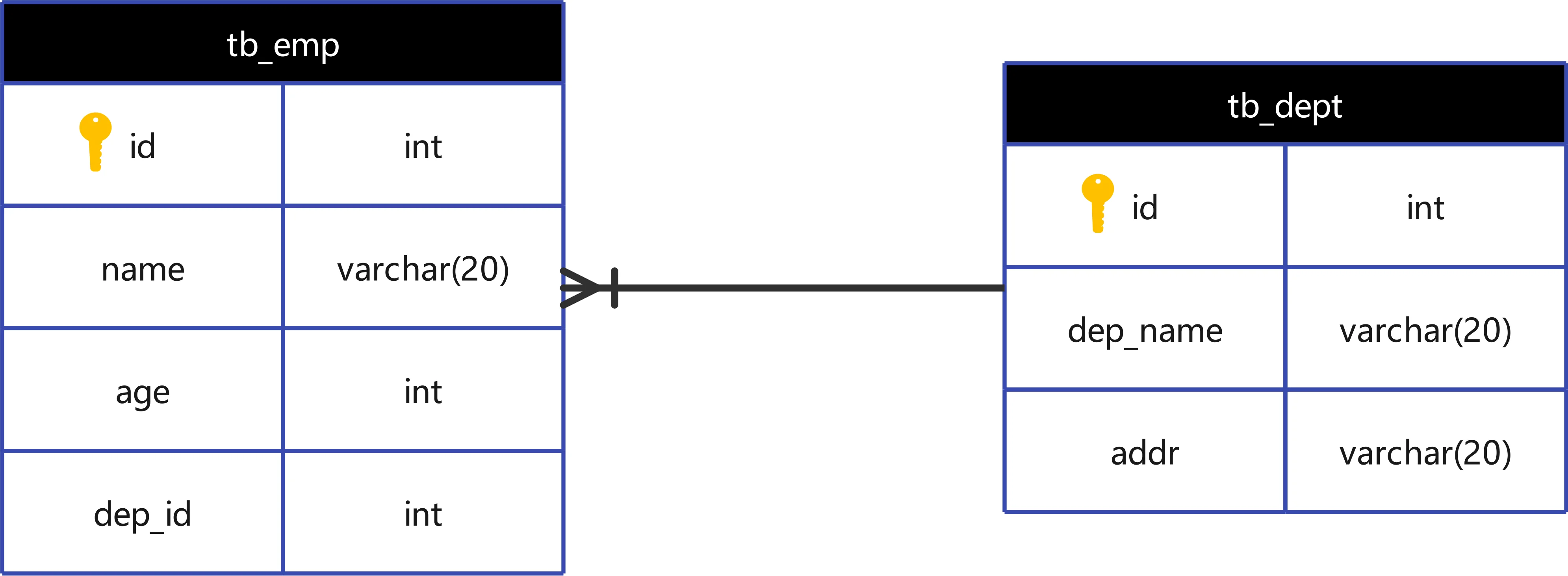
定义:表 A 中的一条记录可以对应表 B 中的多条记录,但表 B 中的一条记录只能对应表 A 中的一条记录。
典型案例:
部门 (1) ↔ 员工 (多)。
班级 (1) ↔ 学生 (多)。
分类 (1) ↔ 商品 (多)。
在 “多” 的一方表中建立外键,指向 “一” 的一方的主键。
口诀:“多”方存外键。
部门与员工
DROP TABLE IF EXISTS tb_emp;
DROP TABLE IF EXISTS tb_dept;
-- 1. "一" 的一方:部门表
CREATE TABLE tb_dept (
id INT PRIMARY KEY AUTO_INCREMENT,
dep_name VARCHAR(20) NOT NULL,
addr VARCHAR(20)
);
-- 2. "多" 的一方:员工表 (包含外键)
CREATE TABLE tb_emp (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20),
age INT,
dep_id INT, -- 外键列
CONSTRAINT fk_emp_dept FOREIGN KEY (dep_id) REFERENCES tb_dept(id)
);数据逻辑:
一个部门(如 ID=1 研发部)可以拥有多个员工(张三、李四的 dep_id 都为 1)。
一个员工只能属于一个部门(dep_id 是单值)。
Many-to-Many
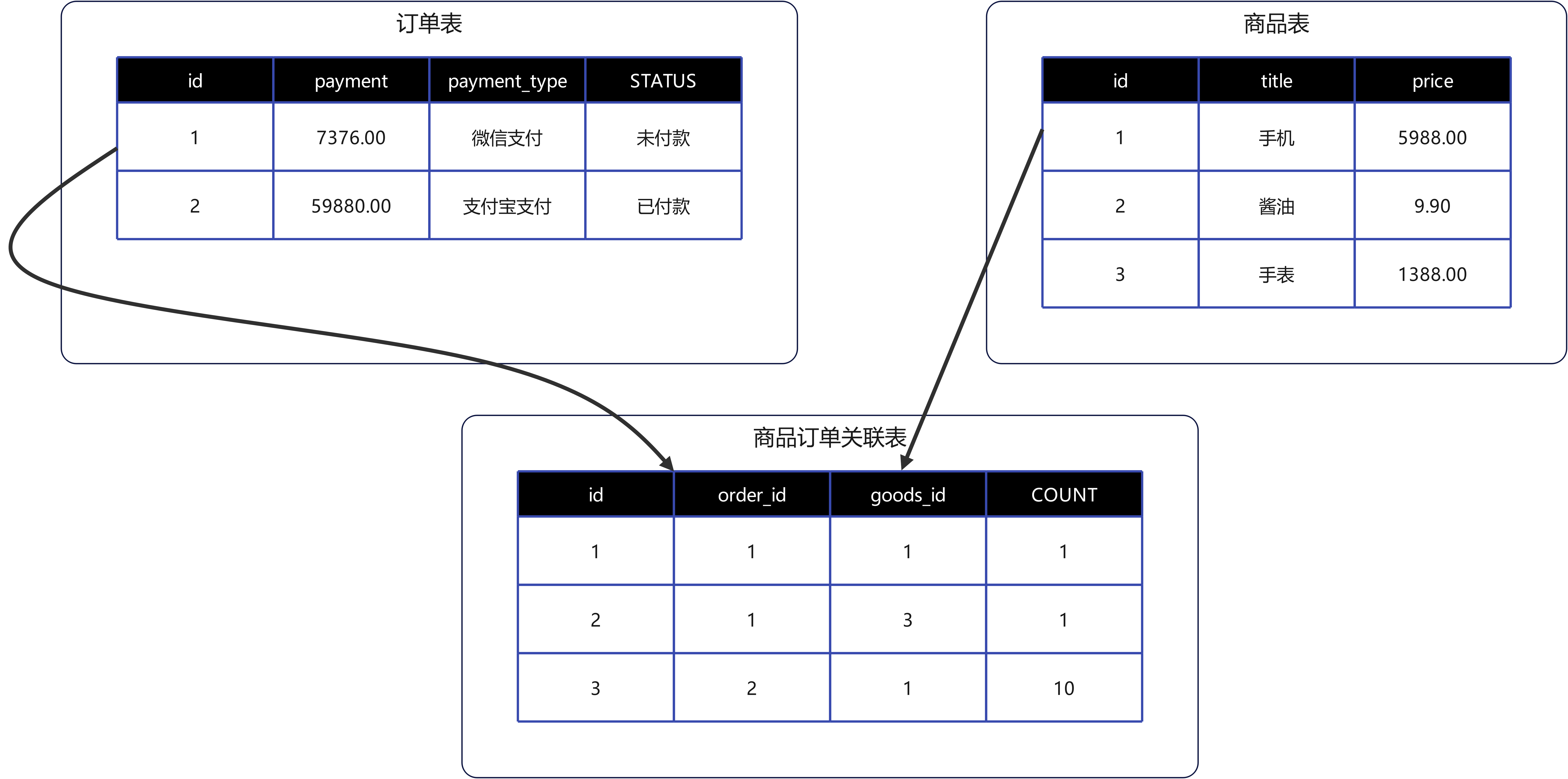
定义:表 A 中的一条记录可以对应表 B 中的多条记录,同时表 B 中的一条记录也可以对应表 A 中的多条记录。
典型案例:
学生 ↔ 课程 (一个学生选多门课,一门课被多个学生选)。
商品 ↔ 订单 (一个订单含多个商品,一个商品出现在多个订单中)。
用户 ↔ 角色 (一个用户有多个角色,一个角色赋予多个用户)。
必须创建第三张中间表 (关联表)。
中间表至少包含两个外键,分别指向两张主表的主键。
这两个外键的组合通常作为中间表的联合主键,以防止重复关联。
订单与商品
DROP TABLE IF EXISTS tb_order_goods;
DROP TABLE IF EXISTS tb_order;
DROP TABLE IF EXISTS tb_goods;
-- 1. 订单表
CREATE TABLE tb_order (
id INT PRIMARY KEY AUTO_INCREMENT,
payment DECIMAL(10, 2),
order_date DATETIME DEFAULT CURRENT_TIMESTAMP
);
-- 2. 商品表
CREATE TABLE tb_goods (
id INT PRIMARY KEY AUTO_INCREMENT,
title VARCHAR(100),
price DECIMAL(10, 2)
);
-- 3. 中间表 (核心)
CREATE TABLE tb_order_goods (
id INT PRIMARY KEY AUTO_INCREMENT,
order_id INT NOT NULL,
goods_id INT NOT NULL,
count INT DEFAULT 1, -- 购买数量
-- 定义外键
CONSTRAINT fk_order FOREIGN KEY (order_id) REFERENCES tb_order(id),
CONSTRAINT fk_goods FOREIGN KEY (goods_id) REFERENCES tb_goods(id),
-- 可选:防止同一订单重复添加同一商品
UNIQUE KEY uk_order_goods (order_id, goods_id)
);数据插入逻辑
假设订单 1 购买了:1 台手机 (ID=1) 和 1 块手表 (ID=3)。
-- 插入基础数据
INSERT INTO tb_goods (title, price) VALUES ('手机', 5988.00), ('酱油', 9.90), ('手表', 1388.00);
INSERT INTO tb_order (payment) VALUES (7376.00); -- 订单 1
-- 插入中间表关联数据
INSERT INTO tb_order_goods (order_id, goods_id, count) VALUES
(1, 1, 1), -- 订单 1 买了 1 个手机
(1, 3, 1); -- 订单 1 买了 1 个手表