理解 Java 中字符串的基本概念与内存存储机制
掌握创建字符串的两种方式及其区别
了解 String、StringBuffer、StringBuilder 和 StringTokenizer 的用途与特性
深入理解字符串的不可变性(Immutability)及其影响
熟悉字符串常量池(String Constant Pool)的工作原理
在 Java 中,String 是一个用于存储字符序列的对象,这些字符被双引号包围,并以 UTF-16 编码(每个字符占 16 位)存储。从功能上看,字符串的行为类似于字符数组。Java 提供了强大且灵活的字符串 API,支持拼接、比较、查找、替换等多种操作。
String name = "Coder";
String num = "5678";静态内存(字符串常量池)
String str = "CoderHub";JVM 会先检查字符串常量池中是否已存在值为 "CoderHub" 的对象。
如果存在,则直接复用该对象,不创建新对象,提高内存效率。
如果不存在,则在常量池中创建该对象。
✅ 推荐方式:更节省内存,性能更优。
new 关键字堆内存(Heap)
String s = new String("Welcome");无论常量池中是否存在 "Welcome",JVM 都会在堆内存中创建一个新的 String 对象。
同时,字面量 "Welcome" 会被放入字符串常量池(如果尚未存在)。
变量 s 指向的是堆中的新对象,而非常量池中的对象。
⚠️ 注意:这种方式会强制创建新对象,即使内容相同。
示例对比:
String s1 = "TAT"; // 常量池
String s2 = "TAT"; // 复用 s1 的对象
String s3 = new String("TAT"); // 堆中新建对象
String s4 = new String("TAT"); // 再次新建对象s1 == s2 → true(引用相同)
s3 == s4 → false(引用不同)
s1.equals(s3) → true(内容相同)
CharSequence 接口表示字符序列的通用接口,定义了以下方法:
length():返回长度
charAt(int index):获取指定位置字符
subSequence(int start, int end):截取子序列
toString():转为字符串
实现该接口的主要类包括:
String 不可变字符串
一旦创建,内容不可更改。
所有“修改”操作(如 concat()、replace())都会返回新对象,原对象不变。
示例:不可变性演示
String s = "Alice";
s.concat(" Wonderland"); // 返回新字符串,但 s 未变
System.out.println(s); // 输出:Alice若要保留修改结果,需显式赋值:
s = s.concat(" Wonderland");
System.out.println(s); // 输出:Alice WonderlandStringBuffer 可变 & 线程安全
内容可修改(通过 append()、insert() 等方法)。
线程安全(方法加了 synchronized),适合多线程环境。
性能略低(因同步开销)。
StringBuffer sb = new StringBuffer("Coder");
sb.append("Hub");
System.out.println(sb); // CoderHubStringBuilder 可变 & 非线程安全
与 StringBuffer 功能类似,但不保证线程安全。
单线程下性能更高,是日常开发首选。
StringBuilder sb = new StringBuilder();
sb.append("Code").append("Master");
System.out.println(sb); // CodeMaster💡 建议:单线程用
StringBuilder,多线程共享字符串缓冲区用StringBuffer。
StringTokenizer 字符串分词器
用于将字符串按分隔符拆分为多个“token”(令牌)。
StringTokenizer st = new StringTokenizer("Java String Example");
while (st.hasMoreTokens()) {
System.out.println(st.nextToken());
}
// 输出:
// Java
// String
// Example注意:
StringTokenizer已逐渐被String.split()或Scanner替代,但在某些场景仍有用。
String Constant Pool
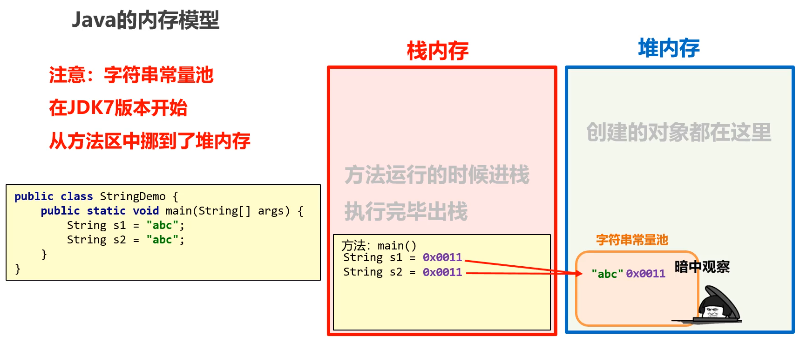
位于 堆内存(Heap)中(自 Java 7 起从永久代 PermGen 迁移而来)。
存储所有通过字面量创建的字符串。
实现“内容相同则复用”的优化策略。
new 创建的字符串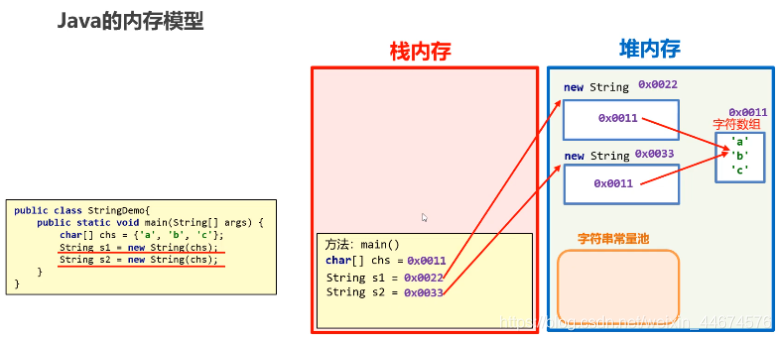
对象存于普通堆内存,不在常量池中。
可通过 .intern() 方法手动将其加入常量池:
String s = new String("Hello");
String interned = s.intern(); // 若常量池无 "Hello",则加入并返回引用;否则返回已有引用就是使用 + 号进行拼接
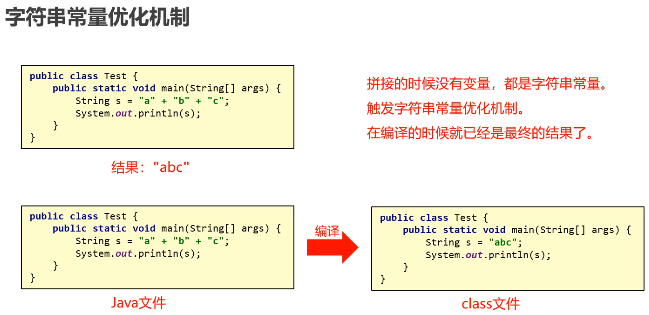
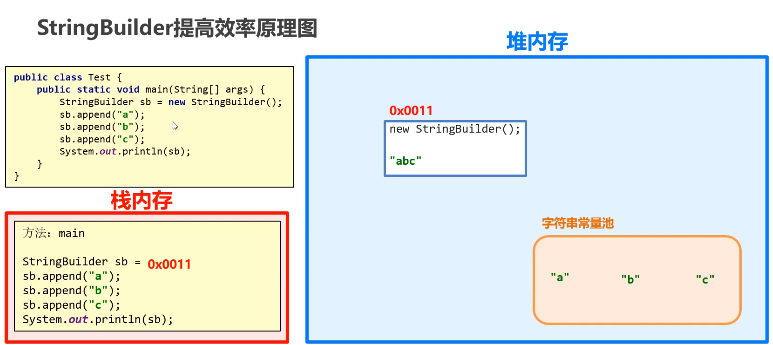
就是使用 StringBuilder 进行拼接,底层其实是在堆内存中创建了一个 StringBuilder 对象进行实现的, 只要出现了一个 + 号至少会在堆内存中创建一个 StringBuilder 对象
String s1 = "abc" ;
String s2 = s1 + "bcd" ;
// 底层实现:new StringBuilder().append(s1).append("bcd").toString();直接 + 的方式拼接字符串:在内存中创建了很多对象,浪费空间,时间也非常慢
不推荐使用
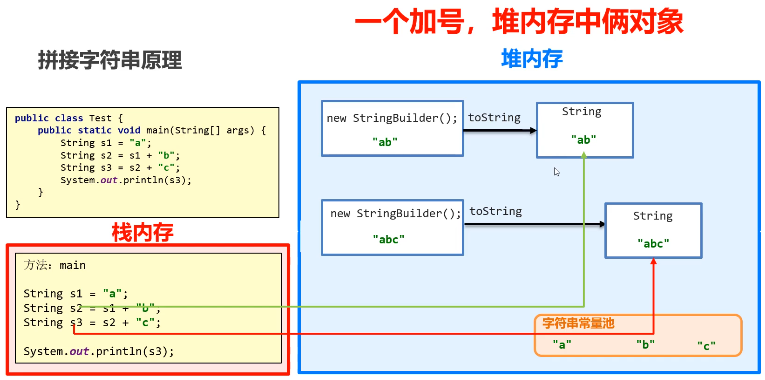
只创建一个 StringBuilder 对象,所有内容都往里面塞
byte ascii[] = { 67, 111, 100, 101 }; // 'C','o','d','e'
String str1 = new String(ascii); // "Code"
String str2 = new String(ascii, 1, 3); // 从索引1开始取3个字节 → "ode"char chars[] = { 'C', 'o', 'd', 'e' };
String s1 = new String(chars); // "Code"
String s2 = new String(s1); // 复制构造Java 6 及之前:字符串常量池位于 PermGen(永久代),空间有限(默认仅 64 MB),易导致 OutOfMemoryError。
Java 7+:常量池迁移到主堆内存,空间更大,管理更灵活。
这一改动显著提升了大量字符串应用的稳定性与性能。
优先使用字符串字面量(如 "text")以利用常量池优化。
避免频繁使用 + 拼接字符串(尤其在循环中),应改用 StringBuilder。
理解 ==(引用比较)与 .equals()(内容比较)的区别。
为什么 Java 将字符串设计为不可变的?这种设计带来了哪些好处和潜在问题?
在以下代码中,共创建了多少个字符串对象?分别位于哪里?
String a = "Hello";
String b = "Hello";
String c = new String("Hello");
String d = c.intern();在高并发 Web 应用中处理用户输入的动态字符串拼接,应选择 StringBuffer 还是 StringBuilder?为什么?